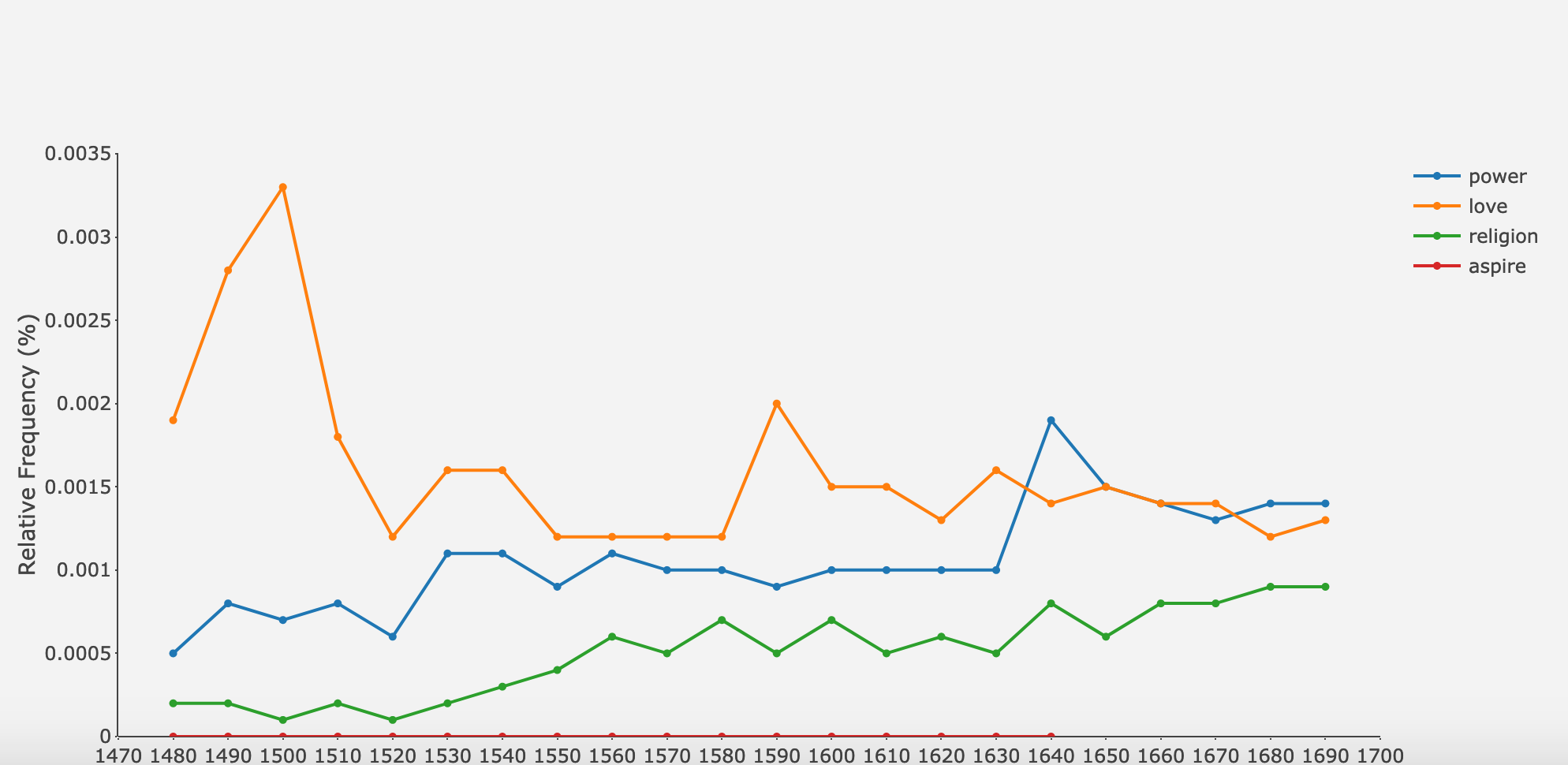
This project seeks to add dimension to the study of English texts from the Early Modern period by seamlessly integrating state-of-the-art data analysis with dynamic corpus exploration. Our corpus of approximately sixty thousand texts, based on the English language texts in the EEBO-TCP archive and adorned with Northwestern University’s MorphAdorner, allows for in-depth computational analysis of Early Modern print at varying scales - from individual word meanings to broad textual themes - to any scholars interested in digital archives.
Through attention both to the essences and alchemical transformations of language in this archive, we are attempting to capture the many senses of the word quintessence that animated Early Modern thought.